Bonjour à toutes et tous,
J’espère publier au bon endroit.
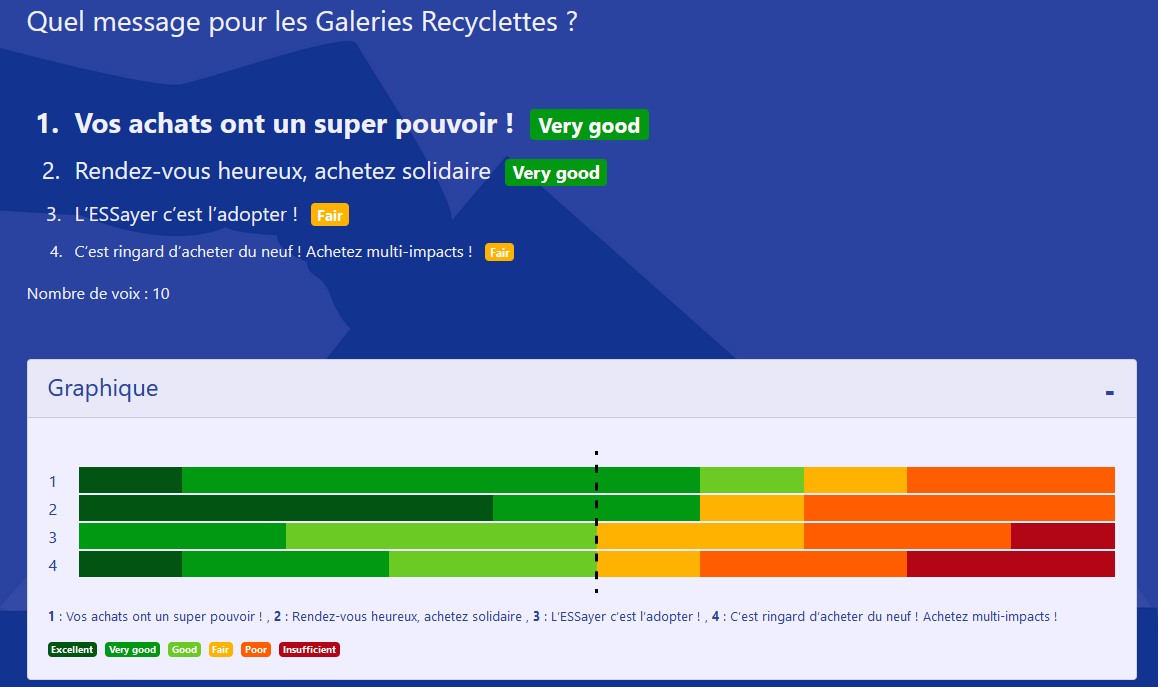
J’ai du mal à comprendre le départage des égalités. Dans l’exemple ci-dessous, je ne comprends pas comment les deux premières places sont départagées, je trouve cela contre intuitif (alors que le reste du processus me parait clair comme de l’eau de roche). Pouvez-vous m’expliquer ?
1 (= Vos achats …) a la même mention majoritaire que 2 (= Rendez-vous …). En cas d’égalité, on retire un vote dans la mention majoritaire pour 1 et 2.
Maintenant, la mention majoritaire de 1 est Bien, tandis que celle de 2 est Passable. 1 est donc le gagnant.
Le cas que vous proposez est malheureusement difficile à analyser graphiquement car il y a très peu de d’électeurs. Avec un grand nombre d’électeurs, une meilleure manière consiste à comparer la proportion de votes en dessous et celle au dessus.
(Quand on leur enlève 1 voix Very Good, leurs mentions majoritaires restent Very Good. Il faut en enlever une 2e pour que leurs mentions majoritaires deviennent respectivement Good et Fair. À part ça, l’explication de @pierre-louis est la bonne. )
Si tu veux, @antoinehuchin, voici une autre méthode, plus complète, qui permet toujours de départager des options ayant des profils différents.
Elle se fait en 2 étapes :
Calculer la jauge majoritaire complète de chaque option
Classer les jauges majoritaires complètes
1. Calculer la jauge majoritaire complète de chaque option
Je prends l’exemple de l’option 1 de ton vote.
Tu pars du profil de mérite :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
0
2
1
1
5
1
Tu calcules les effectifs cumulés croissants et décroissants :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
0
2
1
1
5
1
0
2
3
4
9
10
10
10
8
7
6
1
(Et tu en profites pour vérifier que le total des votants est correct. Ici il y a bien 10 votants.)
Tu repères la mention majoritaire. Par définition, c’est la meilleure mention telle qu’une majorité absolue des votants donne au moins cette mention. Autrement dit, dans les effectifs cumulés décroissants (), c’est, en partant de la droite, la première qui est > 10 / 2 = 5. Ici c’est donc Very Good :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
0
2
1
1
5
1
0
2
3
4
9
10
10
10
8
7
6
1
MM
Pour chaque mention différente de la MM, tu calcules sa force, qui est le minimum des deux lignes et :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
0
2
1
1
5
1
0
2
3
4
9
10
10
10
8
7
6
1
Force
0
2
3
4
MM
1
Tu peux maintenant écrire la jauge majoritaire complète en écrivant la MM suivie des forces des mentions, en ordre décroissant, préfixées par une direction : 🠕 si elle est supérieure à la MM et 🠗 si elle est inférieure :
VG (🠗 4) (🠗 3) (🠗 2) (🠕 1) (🠗 0)
(Si plusieurs mentions ont la même force, celles qui sont 🠗 viennent avant celles qui sont 🠕. Voir par exemple le calcul pour l’option 2, plus bas.)
En détaillant tout comme ça, ça semble un peu long et un peu compliqué, mais en fait on ne fait que des additions et des comparaisons. Avec un peu de pratique (ou un tableur) ça devient vite très facile.
Si ça t’intéresse, entraîne-toi en calculant les jauge majoritaires complètes des autres options du vote.
Voici ce que j’ai obtenu :
Option 2 :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
0
3
1
0
2
4
0
3
4
4
6
10
10
10
7
6
6
4
Force
0
3
4
4
MM
4
VG (🠗 4) (🠗 4) (🠕 4) (🠗 3) (🠗 0)
(Remarquer sur cet exemple que les (🠗 4) viennent avant la (🠕 4).)
Option 3 :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
1
2
2
3
2
0
1
3
5
8
10
10
10
9
7
5
2
0
Force
1
3
MM
5
2
0
(Remarquer sur cet exemple et le suivant que la MM est bien Fair, et non pas Good.)
F (🠕 5) (🠗 3) (🠕 2) (🠗 1) (🠕 0)
Option 4 :
Insufficient
Poor
Fair
Good
Very Good
Excellent
Voix
2
2
1
2
2
1
2
4
5
7
9
10
10
8
6
5
3
1
Force
2
4
MM
5
3
1
F (🠕 5) (🠗 4) (🠕 3) (🠗 2) (🠕 1)
On a donc finalement :
Option
Jauge majoritaire complète
1
VG (🠗 4) (🠗 3) (🠗 2) (🠕 1) (🠗 0)
2
VG (🠗 4) (🠗 4) (🠕 4) (🠗 3) (🠗 0)
3
F (🠕 5) (🠗 3) (🠕 2) (🠗 1) (🠕 0)
4
F (🠕 5) (🠗 4) (🠕 3) (🠗 2) (🠕 1)
2. Classer les jauges majoritaires complètes
Tout l’intérêt d’avoir calculé les jauges majoritaires complètes, c’est qu’elles sont facile à classer. Pour classer deux jauges majoritaires complètes :
Si les MM sont différentes, les classer selon les MM.
Si elles ont la même MM, trouver la première force de mention qui les distingue, c’est elle qui indique leur classement.
Dans notre exemple :
Les options 1 et 2, qui ont la MM Very Good, sont mieux classées que les options 3 et 4, qui ont la MM Fair. Donc {opt 1, opt 2} > {opt 3, opt 4}.
Pour départager les option 1 et 2, on regarde les forces des autres mentions. Elles ont toutes les deux (🠗 4) donc on l’ignore et on regarde les suivantes. Ensuite l’option 1 a (🠗 3) tandis que l’option 2 a à nouveau (🠗 4). Cette dernière est la plus forte (4 > 3), c’est donc elle qui décide du classement. Comme elle est 🠗, elle indique que l’option 2 est moins bien classée. Donc opt 1 > opt 2.
Le même phénomène se produit pour départager les options 3 et 4 : c’est le (🠗 4) de l’option 4 qui détermine leur classement relatif, et elle indique que l’option 4 est inférieure (🠗). Donc opt 3 > opt 4.
Finalement : opt 1 > opt 2 > opt 3 > opt 4.
Conclusion
Dis-moi ce que tu penses de cette méthode et de cette manière de l’expliquer. J’ai tellement l’habitude de l’utiliser que tout me paraît simple, mais il est sans doute possible d’améliorer ça.
Bonjour,
ce que j’appelle résistance à la charge est la quantité de calcul que ça nécessite. Sur mon serveur à partir de un million de votants et 5 mentions, ça plante. et c’est un bon serveur
Mais j’ai calculé qu’à partir de 10000 votants la deuxième méthode de calcul ne produisait aucune incertitude, les ^mêmes résultats, et elle est énormément plus économique en temps de calcul.
Le recueil des données est un autre problème, qui se résout en y mettant le prix.
Sur mon serveur c’est la mémoire allouée au calcul qui flanche, mais ça peut se régler, ainsi que le temps max de calcul.
Ici on a des données aléatoires, qui ne sont pas non plus très sympa pour les tests puisqu’elles ont tendance à s’homogénéiser : tous les candidats ont presque le même vote, donc il faut beaucoup d’itérations pour résoudre les égalités. Chaque itération reprend le million de votants pour refaire le calcul. Donc on n’utilisera pas cette méthode de calcul alors qu’on a la deuxième méthode qui itère les mentions, et produit dans ce cas les mêmes résultats, en beaucoup moins de temps. Sur les deux méthodes, lire : Jugement majoritaire — Wikipédia
Oui, non, effectivement, ça n’est pas normal. Le calcul du classement à partir des profils de mérite doit se faire en temps constant quel que soit le nombre de votants (en O(n ln(n)) sur le nombre de candidats).
Et effectivement, la méthode où on enlève un vote médian et on recommence n’est pas faite pour être utilisée au delà de quelques dizaines de votants. Elle est une manière simple et intuitive de donner une définition mathématique rigoureuse du JM, mais pas une solution algorithmique efficace.
Pour répondre à ta question, donc, la méthode que j’ai décrite plus haut a, en théorie, la bonne complexité, constante par rapport au nombre de votants, comme la deuxième méthode de Wikipedia. Je n’ai jamais implémenté les deux pour comparer.
oh, et même jusqu’à la limite de dix-mille candidats, on peut utiliser cette première méthode.
La seconde produit beaucoup trop d’incertitudes en-dessous de 1000 votants (quasiment aucune à 10k).
J’ai aussi planché sur une méthode alternative, qui produit aucune incertitude, des résultats équivalents, et une consommation des ressources qui s’ajuste automatiquement à la difficulté de résolution des incertitudes.
Notez que l’algorithme utilisé dans les librairies JM fournies sur le github (Java, Go, PHP, Dart) supporte des milliards de participants sans broncher. L’usage de RAM et de CPU est identique quel que soit le nombre de participants.
C’est un algorithme basé sur un calcul de score pour chaque proposition, puis un tri sur le score pour obtenir le rang de chaque proposition.
Le calcul du score est détaillé ici.
C’est le même principe que dans le papier, mais adapté aux exigences informatiques.
Merci d’avoir pris le temps d’écrire tout ça, @domi41. J’ai l’impression que le score que tu décris est isomorphe à ce que j’ai appelé jauge majoritaire complète dans mon explication plus haut.
Cet article était déjà écrit (ton explication est très bien), et je préfère jauge majoritaire complète à score. Je prends note !
J’espère en tout cas que ça aidera @dav à coder un algo qui résiste à la montée en charge. On peut même atteindre des millions de candidats grâce à la parallelisation.
Merci pour cette attention !
J’ai lu le code, j’ai trouvé astucieuse l’idée d’utiliser un usort().
Il est évident qu’avec la méthode de départage des égalités utilisée, peu importe le nombre de votants puisque le calcul se fait sur la base des pourcentages. Les autres méthodes, qui produisent moins d’incertitudes sur des scrutins avec peu de votants, sont nécessairement plus complexes.
J’aurais une question (que j’aurais aimé poser à l’auteur de cette méthode de départage), c’est comment faut-il se comporter pour discriminer des groupes d’égalités ? Dans cet exemple, quand quatre exæquo sont départagés en 2x2 exæquo, on relance un tour, mais on ne conserve plus l’information d’ordonnancement entre les deux groupes, l’un étant au-dessus de l’autre. L’itération suivante peut très bien déjouer cette première approximation (ou me trompé-je ?).
J’ai choisi de lancer des départages successifs pour chaque groupe d’égalité.
En utilisant l’exemple donné, voici le code à entrer dans la machine (Referendum) :
,pizza,chips,pasta,bread
3,2,2,3
2,4,2,2
3,2,3,2
1,3,4,2
Merci pour toutes vos réponses. J’avoue que je ne cherchais pas un débat d’experts et que c’est trop technique pour moi, je cherche plus à comprendre le principe éthique qui meut cela. Pour moi, ce n’est toujours pas clair ou cohérent. Je m’explique :
Je suis séduit par le jugement majoritaire car j’ai une culture de la décision au consentement (sociocratie). Du coup, faire un départage d’égalités en faveur d’un résultat que certains trouvent à rejeter (ce n’est pas le cas dans mon exemple) me parait être en ce sens contre-intuitif. Mon intuition d’un système juste serait que les mentions les moins bonnes, dans ces cas là, puissent peser, pour que le moins de personnes possible ne rejettent la décision finale. Je ne sais pas si je suis clair ?
Ça me paraît assez clair. Par exemple, pour reprendre l’exemple que tu donnais dans ton premier message :
les options « Vos achats… » et « Rendez-vous… » ont la même mention majoritaire : Very Good (VG)
pour les départager on regarde combien de personnes ont donné une mention < VG
il y en a 4 pour chaque options, donc ça ne suffit pas, donc on regarde combien ont donné une mention < Good
il y en a 4 pour « Rendez-vous… » et 3 pour « Vos achats… », donc « Rendez-vous… » est davantage rejetée, donc c’est « Vos achats… » qui gagne (en l’occurrence ça donne le même classement que le JM).
Est-ce que j’ai bien compris ? Ou est-ce que c’est encore autre chose que tu avais en tête ?
Un des avantages des méthodes de jugement tels que le jugement majoritaire, est qu’on peut facilement y mettre en place un système de « veto », dans lequel on pourrait définir que x% (inférieur à 50%) de la pire mention (« à rejeter », le nom correspond parfaitement d’ailleurs) serait considéré comme le niveau du veto.
D’ailleurs ça donnerait plus de sens à la différence entre « à rejeter » et « insuffisant » quand on décide qu’avoir « à rejeter » ou « insuffisant » (pour reprendre les 7 mentions historiques) est éliminatoire.
Cette méthode pourrait d’ailleurs avantageusement remplacer les systèmes de majorité qualifiée ou d’unanimité, en dissociant le simple « non » du « veto »
 )
)

{kind=link}